Description #
Given an input string (s) and a pattern (p), implement regular expression matching with support for
.and*.
.Matches any single character.*Matches zero or more of the preceding element.The matching should cover the entire input string (not partial).
Note:
scould be empty and contains only lowercase lettersa-z.pcould be empty and contains only lowercase lettersa-z, and characters like.or*.Example 1:
Input: s = "aa" p = "a" Output: falseExplanation: “a” does not match the entire string “aa”.
Example 2:
Input: s = "aa" p = "a*" Output: trueExplanation: ‘*’ means zero or more of the preceding element, ‘a’. Therefore, by repeating ‘a’ once, it becomes “aa”.
Example 3:
Input: s = "ab" p = ".*" Output: trueExplanation: “.*” means “zero or more (*) of any character (.)”.
Example 4:
Input: s = "aab" p = "c*a*b" Output: trueExplanation: c can be repeated 0 times, a can be repeated 1 time. Therefore, it matches “aab”.
Example 5:
Input: s = "mississippi" p = "mis*is*p*." Output: false
(From the problem description)
Test Vectors #
| pattern | input | matches? | Comment |
|---|---|---|---|
| a | a | yes | |
| a | b | no | |
| a | aa | no | input to long |
| ab | ab | yes | |
| ab | a | no | input to short |
| . | a | yes | wildcard |
| . | aa | no | input to long |
| .* | (any) | yes | This includes the empty string |
| a* | aa | yes | star operator |
| a* | a | yes | |
| a* | \(\epsilon\) | yes | |
| c*a*b | aab | yes | |
| mis*is*p* | mississippi | no | |
| a*a | a | yes | |
| a*a | aaaa | yes | This tests the backtracking for the last “a” since it will first be consumed by a* |
| .*.*a | aaaa | yes | This tests the backtracking for the last “a” since it will first be consumed by any of the two .* |
Solutions #
Without the * operator this would be a trivial problem. Unfortunately the *
operator has to be dealt with. In essence, problem #10 describes a subset of the regular
expressions found in most languages/tools.
A regular expression describes regular language \(\mathcal{L}\). The problem statement can be rewritten as: Write a program that can take the description of a regular language \(\mathcal{L}\) (regular expression), and a word (input) and decide if \(input \in \mathcal{L}\).
Regular languages are also known as type 3 languages (as defined by Noam Chomsky). The interesting thing about regular languages is that they have the same power of expression as finite state machines.
Finite state machines can be expressed as DFA or NFA. In both cases they show an undesired exponential behavior. An NFA can show exponential runtime while matching a pattern, and a DFA can show exponential memory consumption for the state machine (this also results in exponential time spent constructing the state machine). A DFA often makes sense if the same pattern is tested many times.
Long story short, I implemented two different angles at tackling this problem (both with linear space complexity and worst case exponential runtime complexity):
- Simple recursion
- A straight forward “by the book” recursive implementation.
- Classical lexer, parser, interpreter
- The pattern is analyzed and compiled in a multi
step process.
Solution::isMatchthen interprets the compiled pattern.Surprisingly the solution with lexer, parser, and interpreter is not slower than the recursive solution. For some edge cases it is substantially faster because it includes an optimizer that merges redundant rules.
Problem API #
class Solution:
def isMatch(self, input: str, pattern: str) -> bool:
Tests #
All of the tests analyze the quite simple business rules. In order to keep the amount of red tape limited the test functions test more than one aspect (which normally is scorned upon).
import pytest
class BaseTestClass:
def test_detect_star_at_start_error(self):
with pytest.raises(ValueError):
self.isMatch(input="cab", pattern="*")
def test_detect_star_star_error(self):
with pytest.raises(ValueError):
self.isMatch(input="cab", pattern="a**")
def test_empty_pattern(self):
assert not self.isMatch(input="any", pattern=""), "An empty pattern " \
"only matches the " \
"empty string"
assert self.isMatch(input="", pattern=""), "An empty pattern " \
"only matches the " \
"empty string"
def test_dot(self):
assert self.isMatch(input="a", pattern=".")
assert self.isMatch(input="a", pattern=".")
assert self.isMatch(input="aaa", pattern=".a.")
assert not self.isMatch(input="a", pattern=".."), "input string to " \
"short"
assert self.isMatch(input="any", pattern="...")
def test_abc(self):
p="abc"
assert self.isMatch(input="abc", pattern=p)
assert not self.isMatch(input="c", pattern=p)
assert not self.isMatch(input="a", pattern=p)
assert not self.isMatch(input="", pattern=p)
def test_dot_star_matches_all_to_the_end(self):
assert self.isMatch(input="abc", pattern=".*")
def test_dot_star_matches_at_start(self):
assert self.isMatch(input="abc", pattern=".*c")
def test_a_star_matches_ampty_string(self):
assert self.isMatch(input="", pattern="a*")
def test_backtracking(self):
p="a*a"
assert self.isMatch(input="a", pattern=p)
assert not self.isMatch(input="ab", pattern=p)
assert not self.isMatch(input="aba", pattern=p)
assert self.isMatch(input="aa", pattern=p)
assert self.isMatch(input="aaa", pattern=p)
assert self.isMatch(input="any", pattern=".*")
assert self.isMatch(input="aaa", pattern=".*a.*")
assert self.isMatch(input="ababababab", pattern=".*a.*")
def test_cab(self):
p="c*a*b"
assert self.isMatch(input="cab", pattern=p)
assert not self.isMatch(input="c", pattern=p)
assert not self.isMatch(input="a", pattern=p)
assert self.isMatch(input="b", pattern=p)
assert self.isMatch(input="cb", pattern=p)
assert self.isMatch(input="ab", pattern=p)
assert self.isMatch(input="ccab", pattern=p)
assert self.isMatch(input="ccb", pattern=p)
assert not self.isMatch(input="ca", pattern=p)
import pytest
import collections
"""
These tests use pytest-benchmark (https://pypi.org/project/pytest-benchmark/)
"""
TestCase = collections.namedtuple('TestCase', 'pattern input accepts')
test_cases = [
TestCase(pattern="a", input="a", accepts=True),
TestCase(pattern="a", input="b", accepts=False),
TestCase(pattern="aa", input="a", accepts=False),
TestCase(pattern="a", input="aa", accepts=False),
TestCase(pattern="c*a*b", input="aab", accepts=True),
TestCase(pattern="mis*is*p*", input="mississippi", accepts=False),
]
class BaseBenchmarkClass:
# Generate test cases that enforce massive amounts of backtracking
BENCHMARK_NESTED_STAR_COUNT = 8
@pytest.mark.parametrize("tc", test_cases)
def test_cases(self, benchmark, tc):
message = f"The pattern '{tc.pattern}' should {'' if tc.accepts else 'not'} accept '{tc.input}.'"
result = benchmark(self.isMatch, input=tc.input, pattern=tc.pattern)
assert tc.accepts == result, message
def test_long_dotstar_matching(self, benchmark):
long_pattern=".*" * BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT + \
"a"* BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT
long_matching_text = "a" * \
BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT
assert benchmark(self.isMatch, input=long_matching_text,
pattern=long_pattern)
def test_long_dotstar_not_matching(self, benchmark):
long_pattern=".*" * BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT + \
"a"* BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT
long_matching_text = "a" * \
BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT
long_non_matching_text = long_matching_text + "b"
assert not benchmark(self.isMatch, input=long_non_matching_text,
pattern=long_pattern)
def test_long_bstar(self, benchmark):
long_pattern="b*" * BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT + "b"*BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT
long_matching_text = "b" * BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT
long_non_matching_text = long_matching_text + "a"
assert benchmark(self.isMatch,input=long_matching_text,
pattern=long_pattern)
def test_long_bstar_not_matching(self, benchmark):
long_pattern="b*" * BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT + "b"*BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT
long_matching_text = "b" * BaseBenchmarkClass.BENCHMARK_NESTED_STAR_COUNT
long_non_matching_text = long_matching_text + "a"
assert not benchmark(self.isMatch,input=long_non_matching_text,
pattern=long_pattern)
Solution 1: Recursive #
The most straight forward solution is plain recursion.
class Solution(object):
def isMatch(self, text, pattern):
def match(idx_text: int, idx_pattern: int) -> bool:
pattern_eof = idx_pattern >= len(pattern)
text_eof = idx_text >= len(text)
# If text and pattern both reach the end at the same
# time we have successfully matched the whole
# string
if pattern_eof:
return text_eof
if not text_eof and pattern[idx_pattern] == '*':
raise ValueError(f"Illegal * in '{pattern}'@{idx_pattern}")
head_matches = not (text_eof or pattern_eof) and (
(text[idx_text] == pattern[idx_pattern]) or
(pattern[idx_pattern] == '.')
)
# No checks are made for valid placements of '*'.
is_star = (idx_pattern + 1) < len(pattern) and \
(pattern[idx_pattern + 1] == '*')
if is_star:
if head_matches:
# Try to consume the current char and continue with the
# same pattern
if match(idx_text + 1, idx_pattern):
return True
else:
# Consuming the current char and continue with the same
# pattern does not work, go to the next pattern.
# Skip two chars in the pattern [len("a*")==2]
return match(idx_text, idx_pattern + 2)
else:
# Try the next rule of the pattern for the current char
# Skip two chars in the pattern [len("a*")==2]
return match(idx_text, idx_pattern + 2)
else:
if head_matches:
return match(idx_text + 1, idx_pattern + 1)
else:
return False
return match(0, 0)
Test Results #
The plain recursive solution also works perfectly, the missing optimizer shows
itself in the test results for test_long_dotstar and test_long_bstar.
============================= test session starts ==============================
platform linux -- Python 3.7.5, pytest-3.10.1, py-1.8.0, pluggy-0.12.0
benchmark: 3.2.2 (defaults: timer=time.perf_counter disable_gc=False min_rounds=5 min_time=0.000005 max_time=1.0 calibration_precision=10 warmup=False warmup_iterations=100000)
rootdir: /home/jens/Documents/leetcode.com/010-regular-expression-matching, inifile:
plugins: benchmark-3.2.2, profiling-1.7.0
collected 10 items
test_1a-solution.py .......... [100%]
============================ slowest test durations ============================
(0.00 durations hidden. Use -vv to show these durations.)
========================== 10 passed in 0.05 seconds ===========================
Tests ran in 0.1990008169959765 seconds

Solution 2: Backtracking with Optimizer #
This is a rather classical solution with lexer, parser, optimizer, and interpreter. Although it looks much more complex
In contrast to the solutions on leetcode this solution does neither use dynamic programming or a pure recursive brute force. The main implementation uses a stack to manage the backtracking state.
An optimizer takes care of a few edge cases that can cost a lot of runtime,
namely patterns of repeating Kleen operators, e.g. .*a*, a*.*, or a*a* are
consolidated into .*, respectively a*. The worst case runtime complexity of
these chained star operators is exponential, so getting rid of them where
possible is a good idea.
The following diagram displays the data flow of this solution:
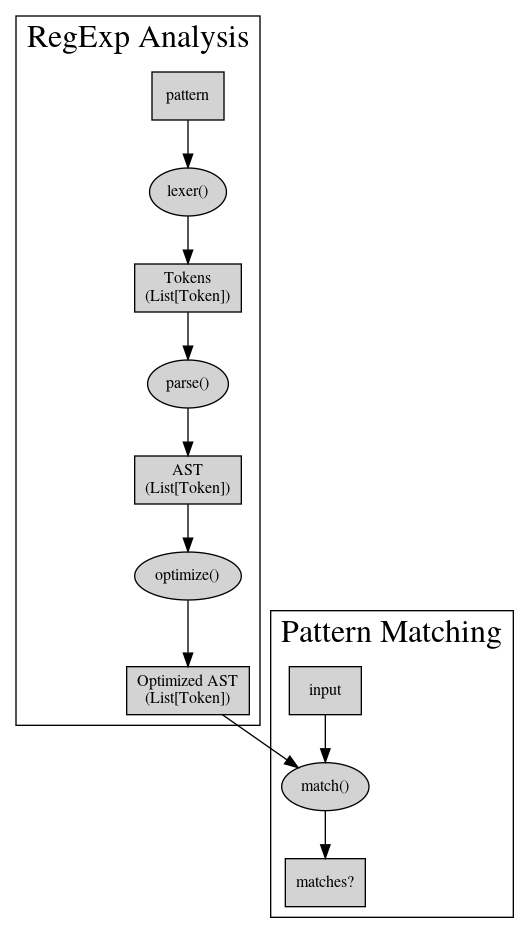
Lexer #
An overly simple lexer that is not strictly necessary.
T_UNKNOWN = 0
T_EOF = 1
T_CHAR = 2
T_DOT = 3
T_STAR = 4
T_TYPES = ["UNKNOWN", "EOF", "CHAR", "DOT", "STAR"]
Token = collections.namedtuple('Token', 'type pattern')
Token.__repr__ = lambda self: f"<type={T_TYPES[self.type]} pattern=" \
f"{self.pattern}>"
EOF = Token(T_EOF, "<EOF>")
def lexer(pattern: str) -> List[Token]:
"""
Tokenizes the pattern. Does not append an T_EOF.
"""
return [
Token(type=T_STAR, pattern="*") if c == "*"
else
Token(type=T_DOT, pattern=".") if c == "."
else
Token(type=T_CHAR, pattern=c) if 'a' <= c <= 'z'
else
Token(type=T_UNKNOWN, pattern=c)
for c in pattern]
Parser #
The parser merges an elementary token (a-z or .) followed by a * into an
ASTish representation. It also appends the EOF marker.
def parse(tokens: List[Token]) -> List[Token]:
"""
The only "special" rule of this grammar is to merge the
STAR rule with the rule *before* the star.
Also detect edge cases like "^*" and "**".
"""
parsed = []
idx = 0
while idx < len(tokens):
eof = (idx + 1) == len(tokens)
lookahead = tokens[idx]
if not eof and tokens[idx + 1].type == T_STAR:
if lookahead.type == T_STAR: raise ValueError(f"Found ** in '"
f"{tokens}@{idx}")
parsed.append(Token(type=T_STAR, pattern=lookahead))
# consume pattern AND '*'
idx += 1
else:
if lookahead.type == T_STAR: raise ValueError(f"Found ^* in '"
f"{tokens}@{idx}")
parsed.append(lookahead)
idx += 1
parsed.append(EOF)
return parsed
Optimizer #
As already described, the optimizer removed some “anti patterns” from the pattern.
def optimize(tokens: List[Token]) -> List[Token]:
if not tokens:
return []
last_rule = None
optimized = []
for r in tokens:
last_rule_star = last_rule and last_rule.type == T_STAR
current_rule_star = r.type == T_STAR
if last_rule_star and current_rule_star:
# a .* and any other X* star can be merged into .*
if last_rule.pattern.type == T_DOT:
continue
elif r.pattern.type == T_DOT:
optimized.pop()
elif r.pattern == last_rule.pattern:
# a*a* == a*
continue
optimized.append(r)
last_rule=r
return optimized
Interpreter #
The interpreter is the heart of the implementation. Lexer, parser and optimizer are more or less sugar coating the implementation.
def matches_elementary(t: Token, c: str) -> bool:
if t.type == T_CHAR:
return t.pattern == c
elif t.type == T_DOT:
return 'a' <= c <= 'z'
elif t.type == T_EOF:
return c == '$'
elif t.type == T_STAR:
return False
def match(parsed: List[Token], input: str) -> bool:
### print(f"test '{input}' against {parsed}")
pstack = collections.deque()
# Add EOF mark
input += "$"
input_idx = 0
token_idx = 0
while True:
backtrack = True
end_of_input = input_idx == len(input)
end_of_pattern = token_idx == len(parsed)
if end_of_input and end_of_pattern:
### print("MATCH")
return True
elif end_of_input:
### print(f"End of input, token : {parsed[token_idx]}@{token_idx} ")
t = parsed[token_idx]
backtrack = True
# for debug ### printout
t = None
i = None
elif end_of_pattern:
### print(f"End of pattern, input : {input[input_idx]}@{input_idx} ")
backtrack = True
# no match because EOF
# for debug ### printout
t = None
i = None
else:
t = parsed[token_idx]
i = input[input_idx]
### print(f"-> test {i}@{input_idx} with {t}@{token_idx}")
if matches_elementary(t, i):
### print("advance pattern, input")
input_idx += 1
token_idx += 1
backtrack = False
elif t.type == T_STAR:
backtrack = False
if matches_elementary(t.pattern, i):
pstack.append((input_idx, token_idx + 1))
### print(f"-> push for backtracking => {pstack} ")
### print("advance input")
input_idx += 1
else:
token_idx += 1
if backtrack:
## print(f"-> backtrack {i}@{input_idx} with {t}@{token_idx}")
if len(pstack) > 0:
input_idx, token_idx = pstack.pop()
### print(f"-> pop from backtracking => (input_idx = "
### f"{input_idx}, token_idx={token_idx}) stack:"
### f" {pstack} ")
else:
### print("NO MATCH (No more backtracking)")
return False
class Solution:
def isMatch(self, input: str, pattern: str) -> bool:
if len(pattern) == 0:
return len(input) == 0
tokens = lexer(pattern)
parsed = parse(tokens)
optimized = optimize(parsed)
return match(optimized, input)
Test Results #
With the following test result:
============================= test session starts ==============================
platform linux -- Python 3.7.5, pytest-3.10.1, py-1.8.0, pluggy-0.12.0
benchmark: 3.2.2 (defaults: timer=time.perf_counter disable_gc=False min_rounds=5 min_time=0.000005 max_time=1.0 calibration_precision=10 warmup=False warmup_iterations=100000)
rootdir: /home/jens/Documents/leetcode.com/010-regular-expression-matching, inifile:
plugins: benchmark-3.2.2, profiling-1.7.0
collected 10 items
test_2a-solution.py .......... [100%]
============================ slowest test durations ============================
(0.00 durations hidden. Use -vv to show these durations.)
========================== 10 passed in 0.03 seconds ===========================
Tests ran in 0.17199079200509004 seconds

Summary #
| Solution | Correct | Status | Runtime | Memory | Language |
|---|---|---|---|---|---|
| #1, recursive | Yes | Not submitted | N/A | N/A | Python3 |
| #2, backtracking w. optimizer | Yes | Submission | 44ms, faster than 86.57% | 12.7 MB, less than 100% | Python3 |